Vectorized evaluation of disjunctive queries
In a previous blog post, I explained how Lucene significantly improved query evaluation efficiency by migrating to a vectorized execution model, and described the algorithm that Lucene uses to evaluate conjunctive queries. In this blog post, I’ll describe the algorithm that Lucene uses to evaluate disjunctive queries, which is a bit more sophisticated.
Block-max WAND (and its many variants) is the dominant query processing algorithm nowadays. If the metric you’re optimizing for is the number of times that you advance any underlying iterator, then it is the best algorithm. However, WAND also comes with overhead: everytime an underlying postings iterator is advanced, the “pivot” doc ID, ie. the minimum doc ID which still has a chance of producing a score that is greater than the current top-k-th score, needs to be re-evaluated.
In fact, after implementing block-max WAND, the Lucene project got several reports of queries that had become slower. Some of them were due to some cases not being properly optimized, e.g. filtered disjunctive queries, but there were also some cases where the slowdown could be 100% attributed to block-max WAND with no obvious fix. It was easy to check: switching to exhaustive evaluation made the query faster.
This is what drove interest in experimenting with the (block-max) MAXSCORE algorithm instead. MAXSCORE works by partitioning clauses into “essential” and “non-essential” clauses. The non-essential clauses are the clauses with the least max scores whose sum of max scores is still less than or equal to the top-k-th score. Essential clauses are all other clauses. Said otherwise, even if all non-essential clauses matched, it would still not be enough for the hit to enter the top-k hit. A document may not enter the top-k heap if it doesn’t match any essential clause. As the query starts processing, all clauses are essential, and as progress is made, more and more clauses migrate to the set of non-essential clauses.
A key property of MAXSCORE that we liked is that the partitioning into essential and non-essential clauses doesn’t need to be performed again on every document, only when the top-k-th score increases. Actually it’s not required to do the partitioning again when the top-k-th score increases, worst-case scenario you’ll just evaluate more documents. It makes it very easy to amortize the overhead of MAXSCORE across many doc IDs, to the point that the overhead of MAXSCORE should be negligible. Said otherwise, you can implement MAXSCORE in a way that it never gets much slower than exhaustive evaluation, something that is impossible with WAND.
A second interesting property of MAXSCORE that we liked is that we could reuse an optimization that had been developed for exhaustive evaluation that Lucene refers to as “BS1”. Evaluating disjunctive queries exhaustively boils down to merging multiple iterators into a single iterator that matches the union of the doc IDs of the underlying iterators. The textbook approach for solving this problem consists of using a heap. But if your doc IDs are densely allocated, you can often do better by accumulating matches into a bit set, and then replaying this bit set. This helps save the overhead of re-ordering the heap on every doc ID of every underlying iterator.
With all that said, let’s look at some Java-like pseudo-code that describes how Lucene evaluates disjunctive queries. First you need iterators of doc IDs:
/**
* Iterator over an ordered set of doc IDs.
*/
interface DocIdSetIterator {
/**
* Return the current doc ID of this iterator, initially -1,
* Integer.MAX_VALUE when the iterator is exhausted.
*/
int docID();
/**
* Given a target that is greater than the current doc ID, advance to the
* first doc ID that is greater than or equal to this target and return it.
*/
int advance(int target);
}
Then Lucene has a Scorer abstraction that enrichs a DocIdSetIterator with
more capabilities related to scoring:
interface Scorer {
/** Return the iterator for this scorer. */
DocIdSetIterator iterator();
/** Compute the score of the current doc ID. */
float score();
/**
* Advance skip data without decoding doc IDs. This is what is called
* NextShallow in the block-max indexes paper. This returns the (inclusive)
* end bounday of the impact block that contains the target doc ID.
*/
int advanceShallow(int target);
/**
* Compute the maximum possible score for doc IDs between the last target
* passed to advanceShallow and the given doc ID (inclusive).
*/
float getMaxScore(int docIdUpTo);
/**
* Return a batch of doc IDs and scores including the current doc ID and up
* to the given doc ID inclusive, and advance the iterator to the first doc
* ID after this batch. Score computations are vectorized when calling this
* method.
*/
(int[], float[]) nextDocsAndScores(int docIdUpTo);
}
And now, here’s Lucene optimized block-max MAXSCORE algorithm. It has two levels of windows: outer windows, which are computed based on the block-max indexes of the underlying clauses, and inner windows, which are used to implement the BS1 optimization with a bounded amount of memory.
int INNER_WINDOW_SIZE = 4_096;
class Accumulator {
BitSet[WINDOW_SIZE] matches;
float[WINDOW_SIZE] scores;
}
/**
* Evaluate the disjunction of the given scorers, loading hits into the given heap.
*/
void evaluateDisjunctiveQuery(Scorer[] scorers, Heap topkHeap) {
for (int outerWindowMin = 0; outerWindowMin != Integer.MAX_VALUE; ) {
// Partition scorers into essential and non-essential scorers based on the
// score upperbounds reported by Scorer#getMaxScore. There is an
// inter-dependency between outer windows and partitions since outer windows
// are computed as the minimum return value of getMaxScore across essential
// clauses, and partitions are computed based on local max scores up to
// outerWindowMax. Since this is not the main point of this blog, the exact
// logic is skipped.
(int outerWindowMax, Scorer[] essentialScorers, Scorer[] nonEssentialScorers) =
partitionScorers(outerWindowMin, scorers, topkHeap.minScore());
// For each non-essential clause, compute the maximum score contribution of
// this clause, plus the next ones.
float[] cumulativeMaxScores = new float[nonEssentialScorers.length];
for (int i = cumulativeMaxScores.length - 1; i >= 0; i--) {
cumulativeMaxScores[i] = nonEssentialScorers[i].getMaxScore(outerWindowMax);
if (i + 1 < cumulativeMaxScores.length) {
cumulativeMaxScores[i] += cumulativeMaxScores[i + 1];
}
}
if (essentialScorers.length == 0) {
// This happens if the sum of all max scores is still less than or equal
// to the top-k-th min score. No competitive hits in this outer window,
// it can be skipped.
} else if (essentialScorers.length == 1) {
evaluateWindowSingleEssentialClause(
outerWindowMax, essentialScorers[0], nonEssentialScorers, cumulativeMaxScores, topkHeap);
} else {
evaluateWindowMultipleEssentialClauses(
outerWindowMax, essentialScorers, nonEssentialScorers, cumulativeMaxScores, topkHeap);
}
outerWindowMin = outerWindowMax;
}
}
void evaluateWindowSingleEssentialClause(
int outerWindowMin,
int outerWindowMax,
Scorer essentialScorer,
Scorer[] nonEssentialScorers,
float[] cumulativeMaxScores,
Heap topkHeap) {
if (essentialScorer.iterator().docID() < outerWindowMin) {
essentialScorer.iterator().advance(outerWindowMin);
}
while (essentialScorer.iterator().docID() < outerWindowMax) {
// Compute a batch of matching doc IDs and their corresponding scores on the
// essential clause. This typically returns 256 entries (the size of postings
// blocks in Lucene). Doc IDs and term frequencies are decoded in batches.
// The computation of BM25 scores uses SIMD instructions.
(int[] docs, float[] scores) = lead.nextDocsAndScores(windowMax);
applyNonEssentialScorersAndCollect(
docs, scores, nonEssentialScorers, cumulativeMaxScores, topkHeap);
}
}
void evaluateWindowMultipleEssentialClauses(
int outerWindowMin,
int outerWindowMax,
Scorer[] essentialScorers,
Scorer[] nonEssentialScorers,
float[] cumulativeMaxScores,
Heap topkHeap) {
// Split the outer window into one or more inner windows whose doc ID range
// doesn't exceed 4,096
for (int innerWindowMin = outerWindowMin;
innerWindowMin < outerWindowMax;
innerWindowMin += INNER_WINDOW_SIZE) {
int innerWindowMax = min(innerWindowMin + INNER_WINDOW_SIZE, outerWindowMax);
Accumulator accumulator = new Accumulator();
for (Scorer scorer : essentialScorers) {
if (scorer.iterator().docID() < innerWindowMin) {
scorer.iterator().advance(innerWindowMin);
}
while (scorer.iterator().docID() < innerWindowMax) {
(int[] docs, float[] scores) = lead.nextDocsAndScores(windowMax);
for (int i = 0; i < docs.length; ++i) {
accumulator.matches.set(docs[i] - innerWindowMin);
accumulator.scores[docs[i] - innerWindowMin] += scores[i];
}
}
}
// Convert the content of the accumulator back to arrays of doc IDs and
// scores by iterating set bits of the `matches` bit set
(int[] docs, float[] scores) = accumulator.matchesAndScores();
applyNonEssentialScorersAndCollect(
docs, scores, nonEssentialScorers, cumulativeMaxScores, topkHeap);
}
}
void applyNonEssentialScorersAndCollect(
int[] docs,
float[] scores,
Scorer[] nonEssentialScorers,
float[] cumulativeMaxScores,
Heap topkHeap) {
for (int i = 0; i < nonEssentialScorers.length; ++i) {
// Hits whose score is not greater than or equal to minRequiredScore have
// no chance to make it to top-k hits
float minRequiredScore = topkHeap.minScore() - cumulativeMaxScores[i];
// Only keep docs and scores whose score is greater than minRequiredScore.
// This is branchless and takes advantage of SIMD instructions.
(docs, scores) = filterByScore(docs, scores, minRequiredScore);
// For each doc that the non-essential clause also matches, increment the
// score by the score produced by this non-essential clause.
scores = applyRequiredClause(nonEssentialScorers[i], docs);
}
for (int i = 0; i < docs.length; i++) {
topkHeap.insert(docs[i], scores[i]); // overflows if more than k entries
}
}
I had to skip a number of details to focus on the most interesting bits. If you would like more details, you can still check out the original code.
Conclusion
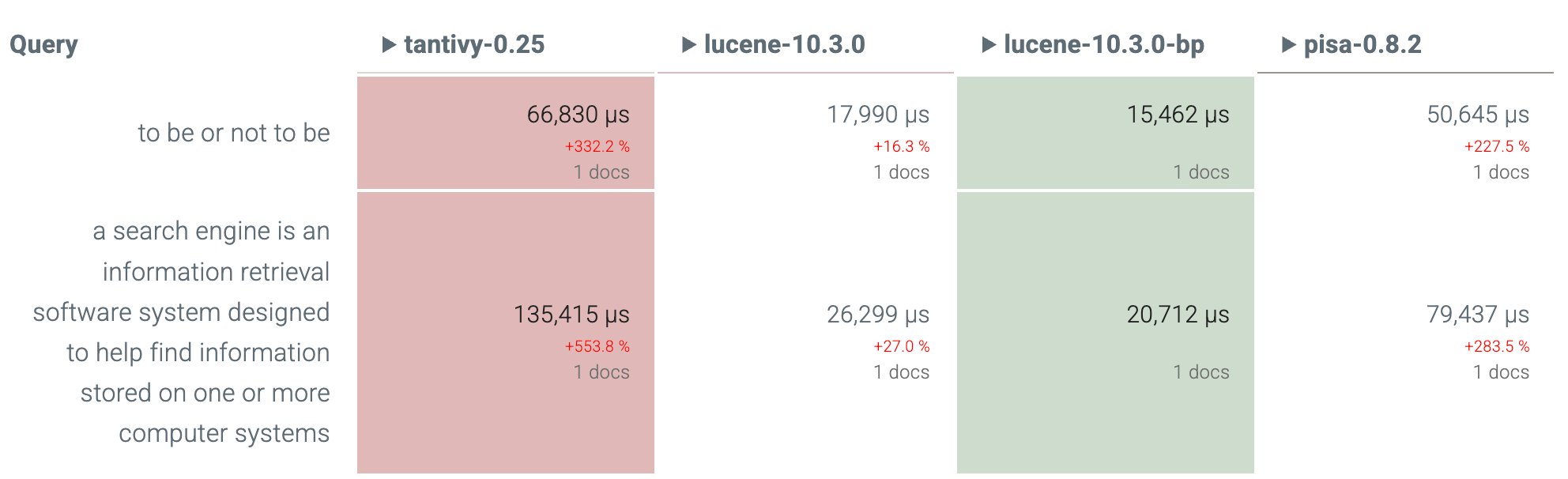
I would like to thank Lucene committers Zach Chen, Guo Feng and Ge Song who helped create an efficient implementation of this algorithm. Lucene is now quite competitive in benchmarks against Tantivy and PISA thanks to this work.
What I especially like about this algorithm is that it optimizes for the harder queries. It may not be the best one if your goal is to optimize your average query latency, but it is quite good at optimizing tail latencies, especially if some of your queries have many terms (e.g. RAG queries that fetch top hits for an entire prompt) or only high-frequency terms (e.g. stop words). For instance, see these two disjunctive queries, which are two of the hardest queries from the benchmark: